기본적인 머신러닝의 용어와 개념 설명 - 모두를 위한 머신러닝(딥러닝의 기본) #01
이 글은 김성훈 교수님의 ‘모두를 위한 머신러닝/딥러닝 강의‘를 학습한 내용을 개인적으로 정리한 글입니다. 때문에 원 강의에서 설명하는 모든 내용을 다루지 않을 수 있으며, 강의에는 포함되어 있지 않은 내용을 추가로 다룰 수 있습니다.
머신러닝이란?
최근 들어 머신러닝(Machine Learning)이라는 용어를 매우 많은 곳에서 듣곤 합니다. 인공지능 분야에서는 기존부터 꽤 주목받고 있던 개념이였지만, 알파고와 이세돌의 대국 이후로는 일반인들 사이에서도 꽤나 주목받는 용어가 된 것 같습니다.
그렇다면 과연 ‘머신러닝’의 정의는 무엇일까요? 비교적 최근에 나온 개념일 것이라 생각하기 쉽지만, 놀랍게도 1959년에 아서 사무엘(Arthur Samuel)에 의해 최초로 정의되었습니다. 아서 사무엘은 머신 러닝을 다음과 같이 정의합니다.
Field of study that gives computers the ability to learn without being explicitly programmed.
이는 한국어로 ‘명시적인 프로그래밍 없이도 컴퓨터가 스스로 학습할 수 있도록 하는 학문’ 정도로 해석할 수 있습니다.
컴퓨터는 복잡한 연산이나 많은 자료를 사람보다 훨씬 빠르고 정확하게 처리할 수 있으며, 이를 위해 필요한 규칙은 대부분 사람이 지정해줍니다. 하지만 이러한 규칙들이 너무 많고 복잡한 경우 이들을 일일히 사람이 지정해주기 매우 어렵습니다.
스팸 메일 필터를 예로 들어봅시다. 스팸 메일을 걸러낼 수 있는 규칙(예: 본문 내 수상한 링크가 포함되어 있음)을 정의하여 이를 규칙에 있는 경우, 해당 규칙과 일치하는 스펨 메일을 거를 수 있습니다. 하지만 이 규칙에는 없는 새로운 형태의 스팸 메일(예: 광고성 이미지만 포함하는 메일)은 찾을 수 없습니다. 때문에 이를 필터링 규칙에 추가해야만 같은 종류의 스팸 메일을 걸러낼 수 있게 됩니다.
스팸 메일의 양이 많은 만큼 그 유형도 매우 다양하기에, 스팸 메일 유형을 프로그래머가 직접 필터링 규칙에 추가하려면 매우 큰 노력이 필요합니다.
최근 기술 개발이 활발히 이뤄지고 있는 자율 주행도 이와 특징이 유사합니다. 자율주행을 위해 필요한 규칙이 너무 많기에 이들을 일일이 프로그래밍하는 것은 현실적으로 매우 어렵습니다.
이러한 한계를 극복하기 위해, 프로그래머가 모든 규칙을 정해주는 대신 ‘프로그램이 데이터를 통해 규칙을 스스로 학습할 수 있으면 어떨까’라는 고민을 하게 되었고, 이러한 주제에 대한 고민들이 ‘머신 러닝’이라는 분야로 자리잡게 되었습니다.
학습이란?
머신러닝에서 프로그램은 ‘학습(Learning)’을 하게 됩니다. 이 때, 학습을 하는 방법에 따라 크게 두 가지로 나눌 수 있습니다.
지도 학습
지도 학습(Supervised Learning)은 특징(features)이 이미 정해진 데이터를 사용하여 학습하는 방법입니다. 이 때 각 데이터에 정해진 특징은 레이블(label)이라고도 표현할 수 있으며, 레이블이 있는 데이터들의 집합은 트레이닝 세트(Training Set)이라고도 부릅니다.
다음은 특정 사물에 해당하는 사진을 짝지어둔 데이터입니다. 사진이라는 데이터에 해당하는 특징(사물)을 짝지어 둔 데이터들의 집합이므로 이는 트레이닝 세트의 한 예로 들 수 있습니다.
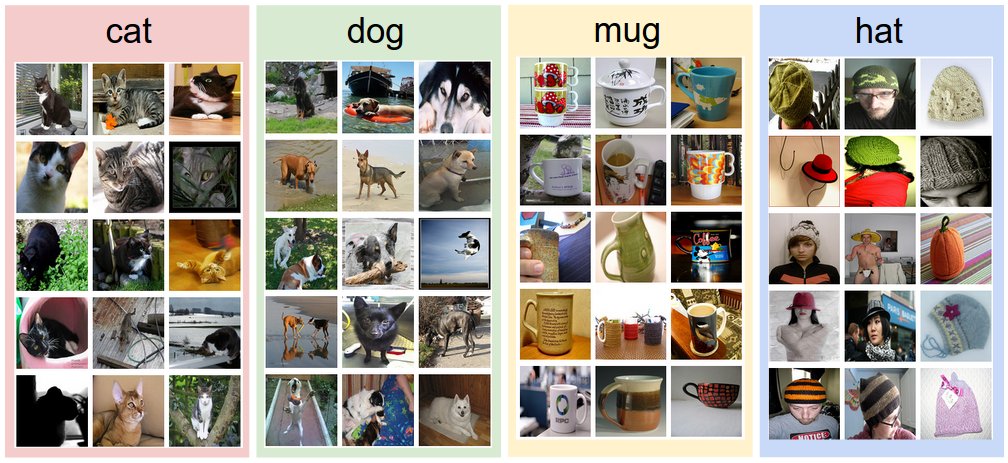
Figure. 트레이닝 세트의 예시1
지도 학습에서는 이와 같은 트레이닝 세트를 통해 각 레이블에 대한 특징을 학습하게 됩니다.
트레이닝 데이터 세트는 다음과 같이 표를 사용하여 표현할 수도 있습니다. 이 표에서 는 자료의 특징을 표현할 때 사용하고, 는 레이블을 의미합니다.
| 3 | 6 | 9 | 3 |
| 2 | 5 | 7 | 2 |
| 2 | 3 | 5 | 1 |
이렇게 주어진 트레이닝 세트를 학습하게 되면 이 데이터들을 기반으로 한 모델이 생성되고, 이 모델을 사용하면 어떠한 특징을 갖는 데이터가 어떤 레이블에 속할지 추측할 수 있게 됩니다.
비지도 학습
비지도 학습(Unsupervised Learning)은 지도 학습과 달리 학습에 사용하는 데이터에 특징(레이블)이 부여되어 있지 않습니다.
지도 학습이 기존에 있는 데이터를 기반으로 새로운 데이터에 대한 특징을 추론하는 것을 목표로 한다면, 비지도 학습은 주어진 데이터들이 어떻게 구성되어있는지를 분석하는 것을 목표로 합니다.
비지도 학습의 대표적인 예로 다음 사례들을 들 수 있습니다.
- 구글 뉴스 서비스: 비슷한 주제의 뉴스끼리 묶어줌
- 단어 클러스터링: 유사한 단어끼리 묶어줌
지도 학습의 유형
지도 학습은 종류에 따라 회귀분석(Regression)과 분류(Classification)으로 나뉩니다.
회귀분석
회귀분석은 어떠한 변수에 영향을 받는 결과가 연속적인2 경우에 사용합니다. 시험 공부에 투자한 시간(변수)에 따라 예상되는 기말고사 점수(0~100 사이의 연속적인 값)을 추측하는 모델을 대표적인 예로 들 수 있습니다.
다음은 시험 공부에 투자한 시간과 실제로 획득한 성적을 담고 있는 트레이닝 세트입니다.
| (time spent for exam) | (score) |
|---|---|
| 10 | 90 |
| 9 | 80 |
| 3 | 50 |
| 2 | 30 |
앞의 트레이닝 세트로 학습시킨 화귀분석 모델을 사용한다면, 시험 공부에 7시간을 투자한 학생의 예상 점수를 대략 75점 정도로 예측할 수 있을 것입니다.
분류
분류는 어떠한 변수에 영향을 받는 결과를 연속적이지 않은 값들로 나눌 때 사용합니다. 시험 공부에 투자한 시간(변수)에 따라 예상되는 합격 여부(Pass/Fail) 혹은 학점 (A/B/C/D/E/F)을 추측하는 모델을 대표적인 예로 들 수 있습니다.
다음은 시험 공부에 투자한 시간과 실제로 획득한 학점(Pass/Fail)를 담고 있는 트레이닝 세트입니다.
| (time spent for exam) | (pass/fail) |
|---|---|
| 10 | P |
| 9 | P |
| 3 | F |
| 2 | F |
여기에서는 데이터를 합격(P) 혹은 불합격(F) 두 가지로 나뉩니다. 따라서 이러한 데이터 구분은 Binary Classification이라 부릅니다.
합격 여부가 아닌 학점을 추측하는 모델을 만드는 경우, 다음과 같은 트레이닝 세트를 사용하게 될 것입니다.
| (time spent for exam) | (grade) |
|---|---|
| 10 | A |
| 9 | B |
| 3 | D |
| 2 | F |
주어진 데이터를 두 개 이상으로 분류하였으므로 이는 Multi-label classification이라 할 수 있습니다.
